

2·
9 months agoI don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)
Programmer in California
I’m also on https://leminal.space/u/hallettj
I don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)
For some more detail see https://dev.to/martiliones/how-i-got-linus-torvalds-in-my-contributors-on-github-3k4g

I did not realize nano implemented syntax highlighting!
It looks like there is at least one work-in-pprogress implementation. I found a Hacker News comment that points to github.com/n0-computer/iroh
Yeah, that makes a lot of sense. If the thinking is that AI learning from others’ works is analogous to humans learning from others’ works then the logical conclusion is that AI is an independent creative, non-human entity. And there is precedent that works created by non-humans cannot be copyrighted. (I’m guessing this is what you are thinking, I just wanted to think it out for myself.)
I’ve been thinking about this issue as two opposing viewpoints:
The logic-in-a-vacuum viewpoint says that AI learning from others’ works is analogous to humans learning from others works. If one is not restricted by copyright, neither should the other be.
The pragmatic viewpoint says that AI imperils human creators, and it’s beneficial to society to put restrictions on its use.
I think historically that kind of pragmatic viewpoint has been steamrolled by the utility of a new technology. But maybe if AI work is not copyrightable that could help somewhat to mitigate screwing people over.
That sounds like a good learning project to me. I think there are two approaches you might take: web scraping, or an API client.
My guess is that web scraping might be easier for getting started because scrapers are easy to set up, and you can find very good documentation. In that case I think Perl is a reasonable choice of language since you’re familiar with it, and I believe it has good scraping libraries. Personally I would go with Typescript since I’m familiar with it, it’s not hard (relatively speaking) to get started with, and I find static type checking helpful for guiding one to a correctly working program.
OTOH if you opt to make a Lemmy API client I think the best language choices are Typescript or Rust because that’s what Lemmy is written in. So you can import the existing API client code. Much as I love Rust, it has a steeper learning curve so I would suggest going with Typescript. The main difficulty with this option is that you might not find much documentation on how to write a custom Lemmy client.
Whatever you choose I find it very helpful to set up LSP integration in vim for whatever language you use, especially if you’re using a statically type-checked language. I’ll be a snob for just a second and say that now that programming support has generally moved to the portable LSP model the difference between vim+LSP and an IDE is that the IDE has a worse editor and a worse integrated terminal.
And there is also Nushell and similar projects. Nushell has a concept with the same purpose as jc where you can install Nushell frontend functions for familiar commands such that the frontends parse output into a structured format, and you also get Nushell auto-completions as part of the package. Some of those frontends are included by default.
As an example if you run ps you get output as a Nushell table where you can select columns, filter rows, etc. Or you can run ^ps to bypass the Nushell frontend and get the old output format.
Of course the trade-off is that Nushell wants to be your whole shell while jc drops into an existing shell.
I’m a fan! I don’t necessarily learn more than I would watching and reading at home. The main value for me is socializing and networking. Also I usually learn about some things I wouldn’t have sought out myself, but which are often interesting.

This is what I use. Or if you don’t need image/PDF embedding or mobile support then VimWiki is a similar solution that is FOSS.
That’s a very nice one! I also enjoy programming ligatures.
I use Cartograph CF. I like to use the handwriting style for built-in keywords. Those are common enough that I identify them by shape. The loopy handwriting helps me to skim over the keywords to focus on the words that are specific to each piece of code.
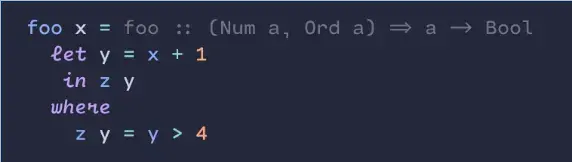
I wish more monospace fonts would use the “m” style from Ubuntu Mono. The middle leg is shortened which makes the glyph look less crowded.
And he has cybernetic nipples!
git rebase --onto is great for stacked branches when you are merging each branch using squash & merge or rebase & merge.
By “stacked branches” I mean creating a branch off of another branch, as opposed to starting all branches from main.
For example imagine you create branch A with multiple commits, and submit a pull request for it. While you are waiting for reviews and CI checks you get onto the next piece of work - but the next task builds on changes from branch A so you create branch B off of A. Eventually branch A is merged to main via squash and merge. Now main has the changes from A, but from git’s perspective main has diverged from B. The squash & merge created a new commit so git doesn’t see it as the same history as the original commits from A that you still have in B’s branch history. You want to bring B up to date with main so you can open a PR for B.
The simplest option is to git merge main into B. But you might end up resolving merge conflicts that you don’t have to. (Edit: This happens if B changes some of the same lines that were previously changed in A.)
Since the files in main are now in the same as state as they were at the start of B’s history you can replay only the commits from B onto main, and get a conflict-free rebase (assuming there are no conflicting changes in main from some other merge). Like this:
$ git rebase --onto main A B
The range A B specifies which commits to replay: not everything after the common ancestor between B and main, only the commits in B that come after A.
Just a guess: I think Inform fits your description

I’m finding this mess interesting: the MAGAs vote and debate like a third party, which kinda gives us a House with no majority party which is something we usually don’t get to see in America. And we’re getting the deadlocks that come from a chamber that isn’t willing to form a coalition - or at least not a reliable one.
I just hope the next speaker candidate doesn’t try for the same Republican-MAGA coalition. Although I’m prepared to be disappointed. Do you think there’s any chance a Republican would offer to sideline the MAGAs to get support from Democrats?
Under this analysis the Democrats have a plurality. How does that tend to work out in governments with more than two parties?
Thanks for the tip about nu_scripts, those look handy!
The expand command is nice. I don’t see how to use it to my mv command work. But that’s not a huge deal.
So maybe this is too much of a kludge, but I happened to see that you can define custom sub-commands to extend existing commands. You can use that to reproduce your familiar command:
def "ls -lrt" [] {
ls | sort-by modified | reverse
}
Of course this does not capture the usual composability of those switches.
Well I might be hooked. It didn’t take me long to reproduce the niceties in Nushell I’m used to from my zsh config. Some of the important parts were setting up zoxide with a key binding for interactive mode, switching on vi key bindings, setting up my starship prompt.
Home Manager is preconfigured for the above integrations which made things easier.
One feature that is missing that I like to use is curly brace expansion to produce multiple arguments. For example,
$ mv *.{jpg,jpeg}
Unless there is a way to do something like this in Nushell that I haven’t seen yet?
Something I enjoyed was automating a sequence of steps I’ve been running a lot lately due to a program that often partially crashes,
def nkill [name_substring] {
ps | where name =~ $name_substring | each { |p| kill $p.pid; $p }
}
I realized after writing this that I basically recreated killall -r. But it’s nice that it was so easy to make a custom command to do a very specific thing. And my version gives me a nice report of exactly what was killed.
Thanks for making this post OP! When I’ve heard mentions of Nushell I’m the past I think I conflated it with Powershell, and wrote it off as a Windows thing. (Maybe because it’s introduced as being “like Powershell”.) But now that I see that it’s cross-platform I’m enjoying digging into it!
I think the best way to get an idea is to look at feature lists for fancy shells like zsh or fish. But in short there are a number of things a good shell can do to help to execute commands faster and more easily. Stuff like autocompletions which make you faster, and also make things more discoverable; fuzzy searching/matching; navigating command history; syntax highlighting which helps to spot errors, and helps to understand the syntax of the command you’re writing.

I remember finding this Practical Engineering video on Roman concrete to be informative: https://youtu.be/qL0BB2PRY7k?si=5exDGyEK_LTfGNOy
Veritasium also has a chapter on ancient concrete in this video: https://youtu.be/rWVAzS5duAs?si=EJ8rPDTPHlq90kgW
My memory is fuzzy, but I think some of the details are:
Definitely see the other comments here about survivorship bias, and higher demands on modern structures.

It scrolls smoothly, it doesn’t snap line by line. Although once the scroll animation is complete the final positions of lines and columns do end up aligned to a grid.
Neovim (as opposed to Vim) is not limited to terminal rendering. It’s designed to be a UI-agnostic backend. It happens that the default frontend runs in a terminal.